Photometric Frequency Analysis
Photometric Frequency Analysis
This objective of this article is to present a detailed description of Photometric frequency analysis and why it is important, along with how do we do data visualization on large datasets. This article contains a few excerpts from scikit-learn Photometric Frequency Analysis post. Also, I used Data Driven Astronomy as a reference while composing this post.
In the current standard cosmological model, the universe began nearly 14 billion years ago, in an explosive event commonly known as the Big Bang. Since then, the very fabric of space has been expanding, so that distant galaxies appear to be moving away from us at very fast speeds. The uniformity of this expansion means that there is a relationship between the distance to a galaxy, and the speed that it appears to be receding from us. This recession speed leads to a shift in the frequency of photons, very similar to the audio doppler shift that can be heard when a car blaring its horn passes by. If a galaxy were moving toward us, its light would be shifted to higher frequencies, or blue-shifted. Because the universe is expanding away from us, distant galaxies appear to be red-shifted: their photons are shifted to lower frequencies.
We’re going to use decision trees to determine the redshifts of galaxies from their photometric colors. We’ll use galaxies whose accurate spectroscopic redshifts have been calculated as our gold standard
We will be using flux magnitudes from the Sloan Digital Sky Survey (SDSS) catalogue to create color indices. Flux magnitudes are the total flux (or light) received in five frequency bands (u, g, r, i and z).
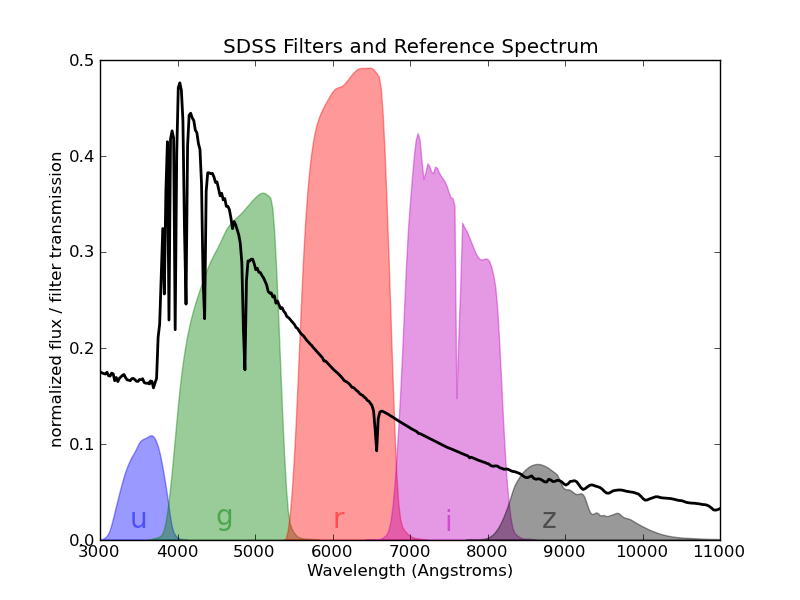
The astronomical color (or color index) is the difference between the magnitudes of two filters, i.e. u - g or i - z. This index is one way to characterize the colors of galaxies. For example, if the u-g index is high then the object is brighter in ultra violet frequencies than it is in visible green frequencies.
Color indices act as an approximation for the spectrum of the object and are useful for classifying stars into different types.
So, lets dive a little deeper into the SDSS data.
We can load the data using numpy and then convert it into a dataframe and view the first 10 rows using the head() function of pandas.
1
2
3
data = np.load('sdss_galaxy_colors (1).npy')
df = pd.DataFrame(data)
df.head(10)
The result would look like -
| u | g | r | i | z | spec_class | redshift | redshift_err | |
|---|---|---|---|---|---|---|---|---|
| 0 | 19.84132 | 19.52656 | 19.46946 | 19.17955 | 19.10763 | b’QSO’ | 0.539301 | 0.000065 |
| 1 | 19.86318 | 18.66298 | 17.84272 | 17.38978 | 17.14313 | b’GALAXY’ | 0.164570 | 0.000012 |
| 2 | 19.97362 | 18.31421 | 17.47922 | 17.07440 | 16.76174 | b’GALAXY’ | 0.041900 | 0.000022 |
| 3 | 19.05989 | 17.49459 | 16.59285 | 16.09412 | 15.70741 | b’GALAXY’ | 0.044277 | 0.000011 |
| 4 | 19.45567 | 18.33084 | 17.67185 | 17.30189 | 17.13650 | b’GALAXY’ | 0.041644 | 0.000018 |
| 5 | 18.27065 | 18.08745 | 18.08966 | 18.22180 | 18.37045 | b’QSO’ | 0.396530 | 0.056599 |
| 6 | 18.94490 | 17.45382 | 16.71061 | 16.26543 | 15.94860 | b’GALAXY’ | 0.073319 | 0.000010 |
| 7 | 19.71360 | 18.72367 | 18.05320 | 17.62663 | 17.39702 | b’GALAXY’ | 0.116479 | 0.000008 |
| 8 | 18.84868 | 16.86433 | 15.90334 | 15.42890 | 15.08823 | b’GALAXY’ | 0.057814 | 0.000016 |
| 9 | 19.76609 | 18.53251 | 17.90900 | 17.48039 | 17.26884 | b’GALAXY’ | 0.081053 | 0.000007 |
Also, its a good practice to look into the statistical measures about our sample. They usually give us more information about the distribution of data.
| u | g | r | i | z | redshift | redshift_err | |
|---|---|---|---|---|---|---|---|
| count | 50000.000000 | 50000.000000 | 50000.000000 | 50000.000000 | 50000.000000 | 50000.000000 | 50000.000000 |
| mean | 19.071964 | 17.773855 | 17.122234 | 16.775569 | 16.538774 | 0.290326 | 0.000120 |
| std | 0.746759 | 0.918719 | 1.080265 | 1.161571 | 1.242212 | 0.539877 | 0.004079 |
| min | 13.422110 | 12.357220 | 11.629170 | 11.051390 | 10.616260 | -0.000513 | 0.000000 |
| 25% | 18.727580 | 17.309120 | 16.512945 | 16.098915 | 15.785885 | 0.064022 | 0.000010 |
| 50% | 19.241820 | 17.850830 | 17.100425 | 16.708060 | 16.438700 | 0.093929 | 0.000016 |
| 75% | 19.617910 | 18.270533 | 17.641098 | 17.292275 | 17.098535 | 0.142451 | 0.000025 |
| max | 19.999940 | 19.991610 | 19.999860 | 19.996950 | 19.984700 | 6.701415 | 0.449662 |
Also, we can visualize the distribution of data in different frequency bands.
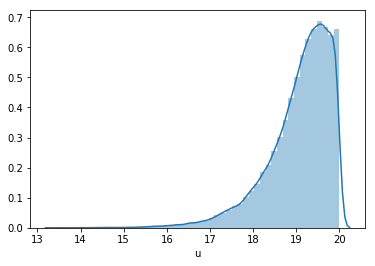
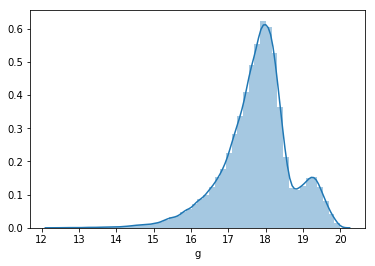
The above images show the frequency distribution of u and g bands respectively.
But we could also plot the distribution of all the frequency bands together.
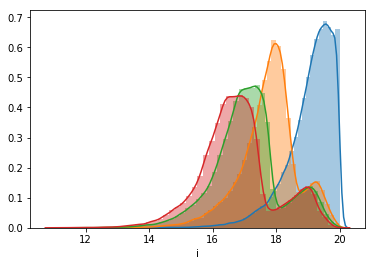
Similarly, we can plot all the different frequency bands against the redshift.
Now to obtain different colors, we’ll subtract the frequency bands, i.e. u-g, g-r etc. After plotting this, this looks like this.
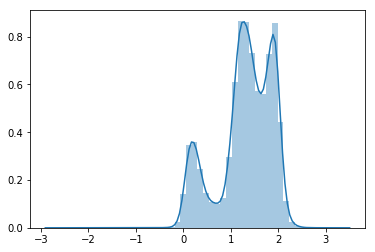
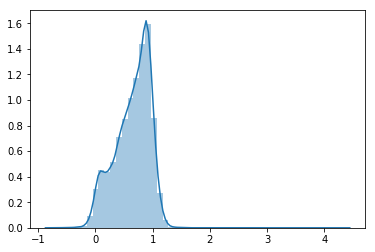
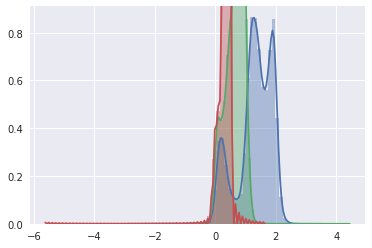
We can again plot them together to obtain something like this.
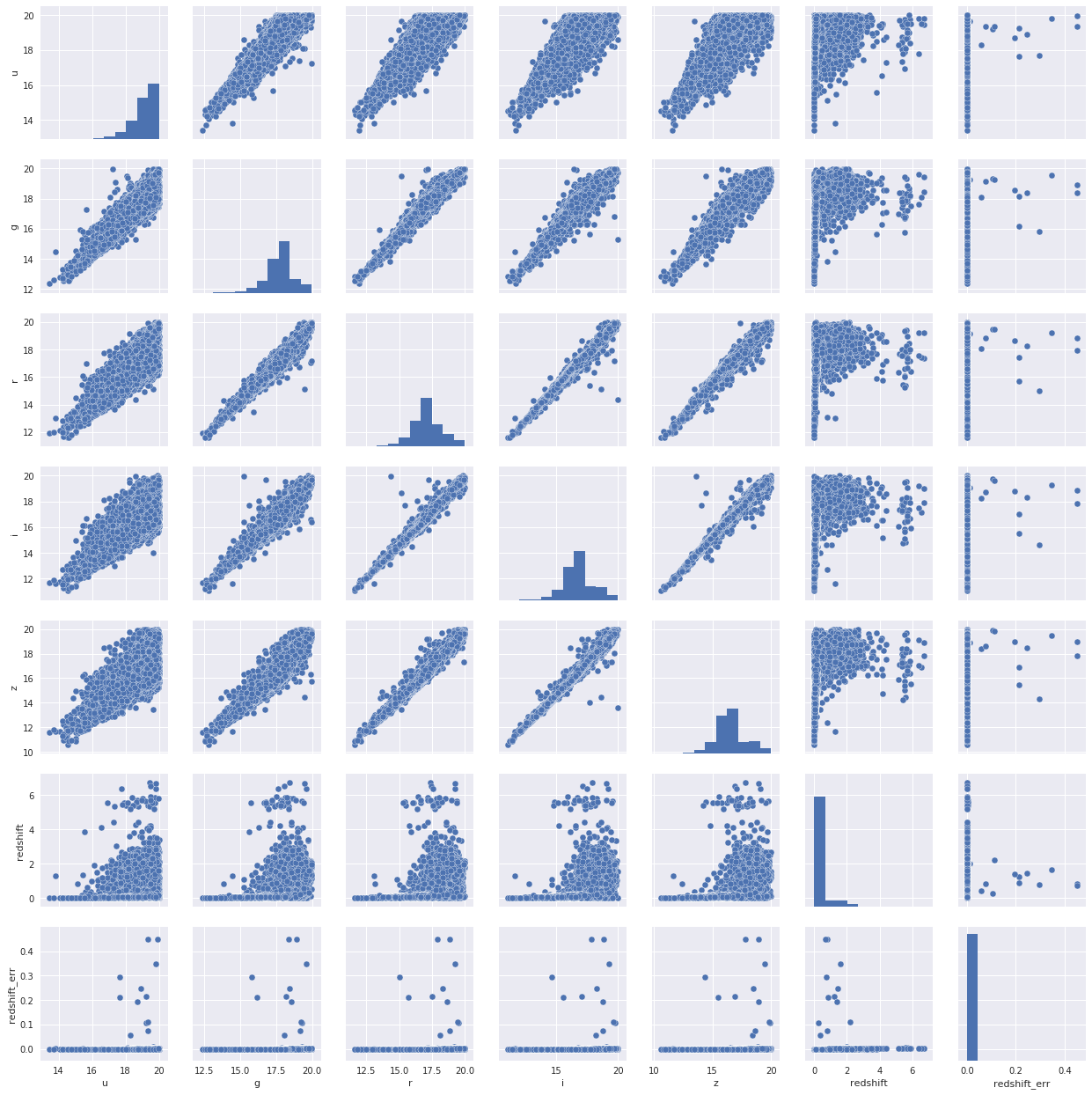
We can also plot a correlation of different features. This map gives us much needed understanding about what effect one parameter has on other parameter.
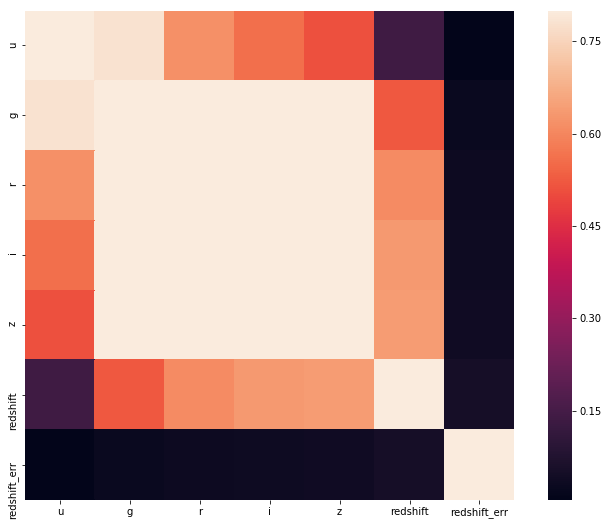
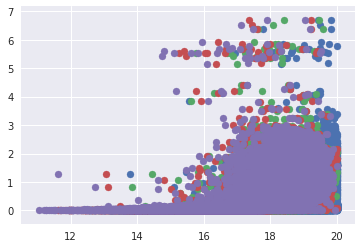
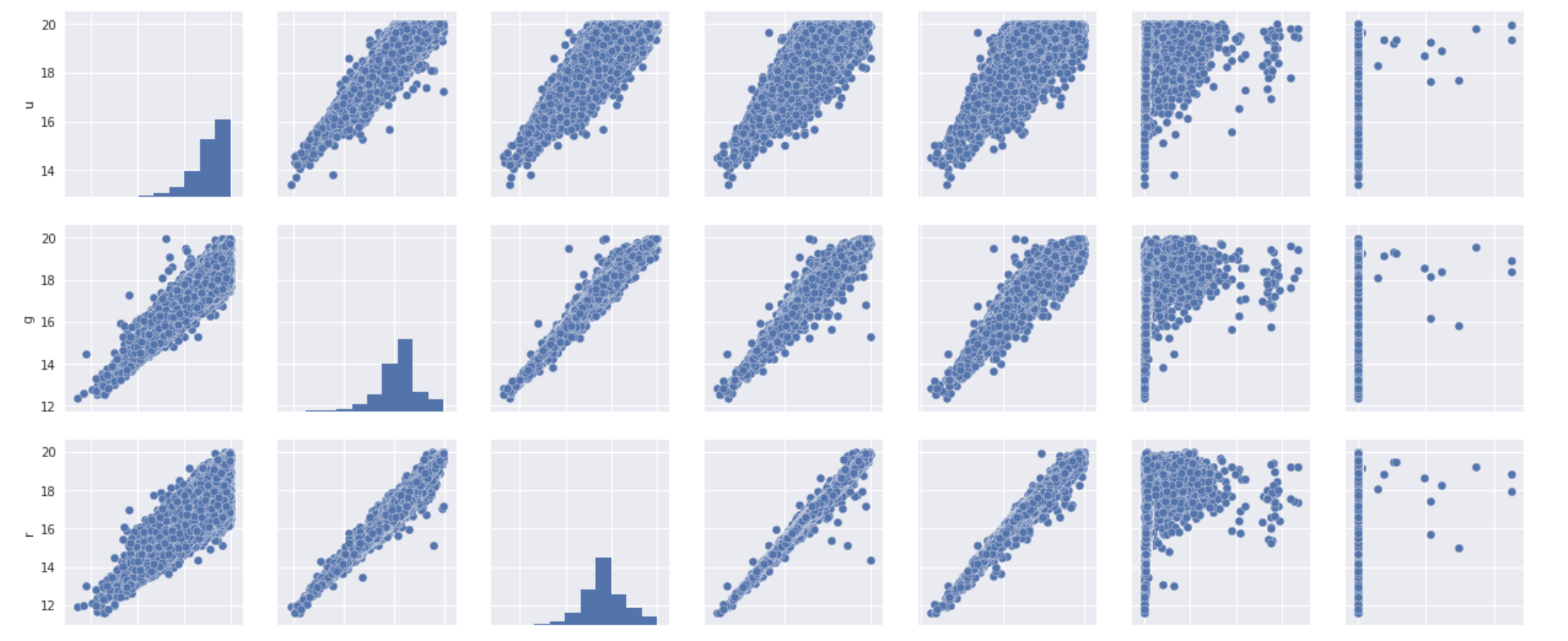
Also, we can plot a scatter plot of all the features combines.
Enough with data visualization !! Lets write some code.
1
2
3
4
5
6
7
8
features = np.zeros((data.shape[0], 4))
features[:,0] = data['u'] - data['g']
features[:,1] = data['g'] - data['r']
features[:,2] = data['r'] - data['i']
features[:,3] = data['i'] - data['z']
targets = np.zeros(data.shape[0])
targets = data['redshift']
Here we are creating features and targets for our classifier.
1
2
3
from sklearn.tree import DecisionTreeRegressor
dtr = DecisionTreeRegressor(max_depth=3)
model = dtr
Then we import the DecisionTreeRegression from the scikit learn library and instantiate it with a maximum tree depth of 3. This is usually done to prevent overfitting.
Now lets divide our data into training and testing data so that we can see how well our classifier is performing.
1
2
3
4
5
6
7
8
9
10
11
# split the data into training and testing features and predictions
split = 45000
train_features = features[:split]
test_features = features[split:]
train_targets = targets[:split]
test_targets = targets[split:]
model.fit(train_features, train_targets)
# get the predicted_redshifts
predictions = model.predict(test_features)
print('Median difference: {:f}'.format(np.median(np.abs(test_targets - predictions))))
When this chunk of code is executed, we get the result as Median difference: 0.038271 which is quite a good accuracy (almost 97%!!).
To understand the distribution of frequency band’s difference (u-g etc.), we can further visualize them using the code below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
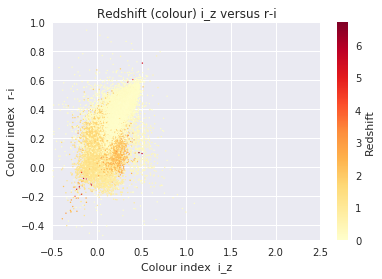
cmap = plt.get_cmap('YlOrRd')
redshift = data['redshift']
# Create the plot with plt.scatter and plt.colorbar
plot = plt.scatter(u_g, r_i, s=2, lw=0, c=redshift, cmap=cmap)
cb = plt.colorbar(plot)
cb.set_label('Redshift')
plt.xlabel('Colour index u-g')
plt.ylabel('Colour index r-i')
plt.title('Redshift (colour) u-g versus r-i')
# Set any axis limits
plt.xlim(-0.5, 2.5)
plt.ylim(-0.5, 1)
plt.show()
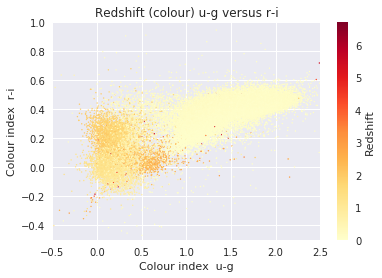
On the conclusion, Obtaining an accurate estimate of the redshift to each of these galaxies is a pivotal part for knowing the galaxy’s history, composition and fate. Since there are so many extremely faint galaxies, there is no possibility of obtaining a spectrum for each one. Thus sophisticated photometric redshift codes will be required to advance our understanding of the Universe, including more precisely understanding the nature of the dark energy that is currently accelerating the cosmic expansion.
Comments powered by Disqus.